

The Future of AI is Vertical
LLMs' Path to Defensibility Through Specialization
While AI has been at the forefront of nearly every software investor’s lexicon for a decade plus, Large Language Models (LLMs) have taken the venture world by storm, turning leaders like OpenAI into household names. One of the biggest challenges we are seeing with LLM-driven applications, however, is defensibility. Today, we’ll discuss why that may be a persistent issue with horizontal approaches to AI and how vertical applications turn that weakness into an advantage. In order to lay the groundwork for our vision of Vertical AI, it’s important to draw context from the history of LLMs and their adoption to date.
A Primer on Generative AI
The term Large Language Model (LLM) emerged about 8 years ago to describe AI leveraging the massive corpus of written data online to train conversational AI models, unlocking a range of emergent content creation (or “generative”) abilities. We will return to some of these details later but in short, modern LLMs are the magic that powers ChatGPT, Midjourney, and many other popular AI models today. As with most science, however, this “breakthrough” was the result of 75 years of AI research.
The famous Turing Test, which examined a machine’s ability to exhibit behavior indistinguishable from a human, was conceived in 1950. AI as a term would be coined 6 years later, and the first “chatbot” (Eliza) would be released a bit over a decade later.1 While most of the recent narrative has focused on post-2017 developments, some of the theoretical considerations around the abilities of generative AI first identified in mid-19th century remain integral to understanding where we’re headed.
The Symbolic Phase
In the 1960’s, two divergent thoughts on artificial intelligence emerged:
“Connectionist AI” was a theory that computers could gain intelligence through learning, similar to our understanding of how human intelligence develops from infancy.
“Symbolic AI” centered around creating programs that leveraged built-in logic, allowing it to imitate forms of human cognition.
Symbolic AI would dominate research and applications for the next 50 years. These models could drastically outperform any humans on any problem with a sufficiently small ruleset, like algebra or chess. However, the limitations of these “rules engines” became clear over the coming decades. Model-based systems proved ineffective at scaling into more complex problems.2 Namely, the scale of pre-programmed knowledge required and difficulty of handling uncertainty caused a rapid plateau in usefulness, ultimately fueling an “AI Winter” in the 1990s and early 2000s which saw funding and interest in the category wane.
Despite the momentary ebbing of AI hype, applied algorithm research—the core of Symbolic AI—never slowed down. PageRank, the famed algorithm used by Google search to rank web page results, is perhaps the most transformative example. Ironically, the rise of Google and its fellow WebScale hegemons Facebook and Amazon (plus Microsoft, eventually) were critical enablers of a resurgence in Connectionist AI. By demanding and building ubiquitous cloud computing infrastructure, they fulfilled a key prerequisite for Machine Learning (ML): significantly cheaper processing power. The cost of compute declined by 1000x from 1990 to 2010.
With cheaper computation and storage, growing investment in novel algorithms, and access to massive amounts of data, the 2010s saw an explosion in ML applications. However, one critical limitation remained: the requirement for human intervention, to facilitate both training architecture and applied decision-making. In some use cases, this can be a feature rather than a bug: consider YouTube’s content recommendation engine, Facebook’s News Feed, or TikTok’s algorithm. Classic ML remains extremely powerful today, despite being currently less in-vogue.
The Rise of Connectionism
In the late 2000s several breakthroughs in Neural Networks ushered an era focused on Deep Learning. From a sufficiently large dataset, Deep Learning algorithms used a massive number of ANN layers to improve at tasks independently, “learning” to extrapolate complex patterns on training data alone, sans Symbolic programming. Supplying such models with sufficient amounts of usable data was (and remains) incredibly time- and resource-intensive. However, as the cost curve of cloud infrastructure continued to decline and GPUs were repurposed for the job, Deep Learning unlocked incredible advancements in self-driving cars, voice assistants, and notably some of the first “generative” applications as researchers began to reverse-engineer image recognition.
Generative AI Today
As with many great scientific achievements, it began as a toy. An image-generation model released by Google in 2015 called “Deep Dream” that captured public attention by generating imagery from text. Just two years later, Attention is All You Need3 (another Google paper) introduced the Transformer architecture enabling LLMs today.4 While the science advanced continuously, LLMs catapulted to public prominence with the launch of OpenAI’s first open version of ChatGPT in November 2022. By training on massive datasets of internet content, with some curation by humans and other special-purpose AIs for QA, ChatGPT was able to “predict” cogent responses to most any user prompt. It made waves in way no AI has since IBM’s Deep Blue, if not ever.
It’s hard to understate the importance of the “large” in these LLMs. GPT-4 had about 500B parameters on release, taking >12 months and at minimum $100M in computing resources to train.5 A critical step forward GPT first made with its v3 was in capacity for “few-shot learning”: the ability to extrapolate patterns based on very few examples.67 This removed the need to collect droves of hyper-specific training data or tweak underlying ML architecture to achieve a baseline in desired skills. In many ways, this was an extension of the anthropomorphic roots of Neural Nets. Humans, after all, are good at intuiting patterns based on limited inputs—throwing a spear 100 million times and measuring the trajectory of each wasn’t really an option for our ancestors. More than anything, throwing volume at the problem just worked. The debate is underway to what extent big competence jumps we saw in GPT-3—“emergent abilities”—can be expected with larger models going forward.8
Has OpenAI Won?
Some still see GPT as the infrastructure choice for future LLM-powered apps. While they may have won the first inning marketing wise, the jury is very much out on their prospects for dominance. OpenAI’s strongest moat is capital, nothing to shake a stick at given the enormous cost of cutting-edge model training. Fast-follower Generative AI models —from Google, Mistral, Anthropic, Cohere, Meta (and its Llama forkers), Hugging Face, Tencent, and yes, Apple and Amazon—are in many cases at parity with OpenAI. And the cycle times are fast. The LLM space is today an arms race in which maintaining the lead for more than a year is exorbitantly expensive and hard defensibility seems fleeting.
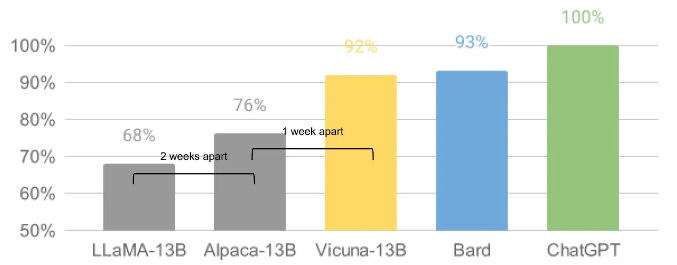
Open-Source LLMs: Substantial Progress at a Fraction of the Cost (via LMSYS)9
Developer response to open-source LLMs have been overwhelming and may be a window into the future. Major improvements, forks, and experimentations are bubbling up daily, and in many cases moving the ball forward where OpenAI et al are not. One critical early innovation of Meta’s Llama, for example, was LoRA (or Low-Rank Adaptation of Large Language Models). This has reduced the size of the requisite training data set by orders of magnitude, allowing developers to update a model in an evening, on commoditized hardware. The other meaningful innovation of LoRA is that improvements to the model can be added in increments. In other words, as better data sets become available, the model can be improved without requiring an entirely new training run. A year ago, Vicuna-13B (Llama fork), benchmarked at about 90% of the response quality of ChatGPT and Google Bard with a training cost of ~$300.
While OpenAI is ahead of the rest at the moment, that open source alternatives are making strong headway at literally a billionth the cost is astounding.
A now-famous internal Google memo—We Have No Moat, And Neither Does OpenAI10—highlighted this point and suggested ceding to public models is an inevitability. Given Google’s roster of talent, unparalleled trove of training corpora, and incentive to stay in front of search disintermediation, we won’t be counting them out any time soon. But the point stands: on their own, LLMs are light on defensibility.

LLM Quality vs. Price from Artificial Analysis11
While the arms race rages on, the current Generative AI landscape favors democratization over monopoly. Many draw the analogy between LLM technology and cloud compute & storage, suggesting a future in which nearly all applications are built on top of an infrastructure layer owned by few. Running data centers and training a cutting-edge LLM, after all, are both capital-intensive undertakings best suited for the deepest pockets. The true picture is much more nuanced:
Discrete model training is seeing rapid cost degression with the current pace of scientific progress. We’re seeing orders of magnitude in cost reduction over 6-month periods for training to a given benchmark; reduction of costs for high-end chips, energy, and real estate are much slower.12 Training data bottlenecks could change that but video remains a blue ocean of tokens.13
Cloud infrastructure is its own economic niche. Emerging players like Anthropic or Mistral have no competitive advantage in building a lower-cost supply of compute or storage in-house vs. current infrastructure providers. Which perhaps explains why both welcomed MSFT on their cap tables, as did OpenAI. Multiple competitive options on both the model and compute front, however, making supply monopolization difficult.
There is strong overlap between the players attempting to dominate cloud and LLM infrastructures, and those players are in fierce competition around big slices of their market cap. Microsoft owning 49% of OpenAI makes some think oligopoly is the future. There are multiple 800-lb gorillas in the pen here: tight control by one just incentivizes the others to undercut or throw their weight behind open-source.
Today’s open-source LLM zeitgeist is a vote of confidence in the future of entrepreneurship and healthy competition in the space. It also bodes well for startups looking to build powerful, domain-specific, AI applications cost-effectively.
The Search for Killer Use Cases
While we believe the path is less straightforward in the B2B world, one killer use case has developed thus far: software development. CoPilot, the result of a GitHub-OpenAI collaboration (Microsoft owning the former and having a sizable stake in the latter), has demonstrated that LLM-based coding assistants can save developers significant time. At least 5 other startups have raised $200M+ to develop competitive LLM-powered coding copilots. The wide availability of code from sources like GitHub provide an ideal training ground for GPT and the extreme symbolic rigor of development languages make them easy for models to understand. With LLMs able to write and test the validity of code independently, availability of training data is less of a rate-limiting factor—the dream (or perhaps nightmare) being a sort of software-developing Von Neumann machine.
We believe coding AI could rival historical platform shifts in enhanced productivity and reduced input cost: workstation to PC, client-server to cloud, web to mobile, etc. Each of these transformations required major underlying IT architecture shifts that took years to effectuate, but eventually increased the reach and capabilities of software applications. It is our hope and belief that any resulting wage depression and job dislocation will be drastically outweighed by the market-expanding potential of this shift. If Generative AI’s sole contribution is driving a downward step-change in the difficulty and cost of software development, that alone could usher in a generational innovation boom across the economy.
There are at least two things we can learn from this first killer use case of LLMs:
If there is a competitive advantage in coding LLMs, it stems from data and workflow (e.g. integration with GitHub repos) rather than the model itself.
The nature of training data—availability, structured-ness, verifiability—plays a key role in how organically LLMs can be applied, suggesting applications outside of language (including code) may not be captured so organically.
Given the proven power of LLM-based AI around discovery and content-generation, it is already difficult to imagine Generative AI playing a role in our weekly, if not daily lives. That said, the promise of LLMs are still in utero. Most AI-driven paradigm shifts of past decades have required the coupling of ML technologies with purpose-built software—and we believe that is certainly the case with LLMs in the enterprise.
The Future of Generative AI is Specialized
We believe most promising B2B application-layer opportunities for LLMs will be vertical, where: (1) harder-to-aggregate or proprietary data is required for model training, (2) the addition of domain-specific symbolic models/experts are necessary for accuracy, and/or (3) layers of workflow software are necessary to deliver real-world impact.
One of the most exciting aspects of LLMs is their generality. In addition to the novelty of being able to converse with an AI fluently, one can’t help but marvel at the model’s versatility, from organizing a data table to writing poetry. For some AI enthusiasts, it feels like at least a partial realization of the Holy Grail: Artificial General Intelligence (AGI), generally defined as a model that matches humans across any cognitive domain. Many of the shortcomings of LLMs have been on public display over the last few years, with confidently wrong answers and other “hallucinations” a pervasive artifact of currently available models. Many argue that the Neural Net architectures underpinning this generation of LLMs are incapable of developing the practical, conceptual knowledge necessary to support logical rigor.
By parsing much of what we’ve written as a species, GPT develops a complex model of syllabic proximity in human language—an “embedding” of meaning only at the semantic level. In other words, while it is a master manipulator of alphanumerics, it is “intelligent” in the sense that it can filter out factual errors in its prose by applying its own objective knowledge of the world.
A Return to Symbolic AI
As introduced earlier in this essay, Connectionist AI involves learning organically, as a human might, whereas Symbolic AI is more rules-based. Stephen Wolfram, amongst others, have argued that elements of Symbolic AI need to be re-introduced into or paired with LLMs to achieve logic, factuality, and reliability.14 One angle with via integration with existing platforms like GPT, which could leverage discrete “domain-expert” algorithms or AIs with mastery of scientific languages and frameworks. GPT does this already when it comes to mathematical analyses and coding. These mixture of experts / agents or “agentic” models are a fast-growing trend today, and it stands to reason are a path to building AI suitable for mission-critical use cases. However achieved, it is clear that high-value enterprise uses of LLMs, will require reliable accuracy ChatGPT et al cannot provide.
Today, we are seeing LLMs applied to nearly every industry but only in use cases that fall below a certain “objective accuracy threshold.” Ad creative generation, legal document first-drafts, and first-line medical scribes are all cases in which getting a fact or two wrong does not sink the ship. As long as human QA time is net-reduced, they are worth it. Value here, however, is driven by natural-language training data that is already generally accessible. Medical diagnosis, industrial product design, or corporate accounting are illustrative of the vertical opportunities that are harder to address today, because:
Hallucinations are more catastrophic, errors being less easily correctable.
Training data in sufficient quantities is likely harder to come by.
Each is predicated on a Symbolic framework unrelated to natural language.
We are seeing similar issues in seemingly “obvious” LLM use cases where the ability to write sensible prose doesn’t cut it. AI personal assistants and SDRs still fall into an uncanny valley failure mode, lacking appropriate handling of context and social dynamics—perhaps the prime achievement of human evolution. As Neural Net architectures were designed with the human brain in mind, it is no surprise that—like us—no NN-family AI will become an expert on anything without ingesting a relevant corpus of data. In the case of natural language fluency, our prolific footprint of blog posts, chats, and digitized text on the internet was more than enough for ChatGPT to become proficient. In a world where models are commodity and data is publicly available, however, founders should ask the same question that Google engineer did in his “leaked” memo: what’s my moat?
The Vertical Path to AI Defensibility
In order to realize its full potential—at least in the commercial world, where we believe much of the dollar opportunity exists—Generative AI must achieve practicality through specialization. This approach will have to expand on developments to date in two primary areas: (1) data aggregation, and (2) software interface.
1. Data Aggregation
For many high-value industry use cases, relevant LLM training data simply does not exist at sufficient volumes in the public domain (e.g. designing blueprints, interfacing with medical patients, parsing insurance claims, dispatching field workers, etc.). In some cases, sufficient data may exist on private servers but be too sensitive or regulated to open up to multi-tenant learning models. In others, data will be available, but without the requisite metadata, requiring tagging by humans (already a big business in its own right) and / or separate AIs. The opportunity is enormous for the entrepreneurs who do the work to aggregate and adapt differentiated datasets to power focused LLM solutions. If breadth of data produced is any indicator of opportunity for LLM applications, the opportunity set in traditional verticals is staggering. Manufacturing, as an example, produces the most data of any industry by a factor of at least 2.15
2. Software Interface
The second critical requirement of Generative AI specialization is a dedicated software layer to translate insights into real-world actions. Natural language, no doubt, has the promise to reimagine the traditional software UI, freeing users from endless menus and buttons—loop in voice and one can imagine a world in which we could even unshackled ourselves from the screen. As it pertains to complex problems, however, dialogue isn’t always the fastest way to relay information to the human brain. Imagine an airline pilot trying to fly a 747 with conversational AI alone.
We see this software layer as a form of Human-Machine Interface (HMI). While HMI traditionally referred to the panels and dashboards engineers use to control a piece of equipment or a factory-floor robot, the HMI we envision here will come in the form of an application software layer with a UI / UX tailored to the use-case. An AI-powered blueprint designer—to continue our earlier example—would need to be able to dynamically display its design choices, parameters, and materials, with functions built to match standard AEC workflows: pull up a comparable building, loop in particular colleagues, integrate data from other tools, etc. UIs evolving beyond point-and-click is an inevitability but without a thoughtful software-based HMI to suit professional workflows, Generative AI will never gain adoption in many critical vertical use cases. Achieving product-market fit, accordingly, will still require founders with deep domain expertise and knowledge of stakeholder behavior in their field.
Multimodality as the New Tech Stack
Multimodal AIs are those that federate multiple models to handle various forms of input / output (e.g. text, video, voice) and / or to perform discrete functions which warrant a dedicated architecture. For example, an app to tutor college students may supplement a base LLM with more Symbolic models that can parse math or science frameworks reliably—ChatGPT’s Wolfram Alpha plugin on steroids. We feel this “mixture of experts” approach is a window into how LLM startups will address complex vertical use-cases, creating a new tech stack that mirrors how SaaS leverages integrations today. This is yet another vote in favor of a diverse and democratized Vertical AI landscape of the future.
In the same way that startup success today has nothing to do with the choice of a cloud provider, Vertical AI winners will not be determined by their base LLM. Model “infrastructure” is already commoditizing and smart founders will seek flexibility to change base models or incorporate multimodal approaches into their stack. Ultimately, we don’t think the determinants of success for Vertical AI are so different from those in traditional software—winners will leveraging deep domain expertise to apply LLMs, access the right partners and datasets, and address a pain point with large dollars at stake.
Euclid’s Approach to the Opportunity
The first and most natural step in our Generative AI research was within the portfolio: working alongside our founders to understand the implications of these technologies for their business and, perhaps more interestingly, identifying opportunities to leverage new open-source LLMs across their product roadmaps. Aggregation of sector-specific, first-party data has been a pillar of our framework since well before the current LLM cycle, something reflected in the Euclid portfolio today. SavorOps, for example, digitizes thousands of invoices a month from its restaurant customers, aggregating the first real-time purchasing data asset across the sector. Both Frontier Risk and MachineryPartner have aggregated millions of unique data points on their customers / assets to power underwriting.
The second important step was to incorporate our learnings around LLMs and identify new investment opportunities within our thesis. We may touch on our approach to roadmapping LLM opportunities future posts. On a high level, however, we’re just extending the “right expertise, right technology” playbook that has served us well: Postmates and Transfix were specialized applications enabled by geolocation and smartphone adoption; HomeLight and BuildingConnected leveraged developments in Big Data management to build category-leading vertical products; and Roofr and Hungryroot leveraged ML to solve discrete, high-value customer problems and take market share.
While our underwriting framework to pick winners must evolve with the times, its fundamental tenets remain unchanged. Recent developments have reinforced certain pillars of our process: the ability to build a “Vertical Data Moat”—a long-time heuristic of ours—is more critical now than ever. LLMs have facilitated new wedge strategies, extending the promise of vertical software to previously ill-suited markets. No doubt, Vertical AI is a major accelerant to Euclid’s thesis and opportunity. Our core mandate, however, remains the same: partnering with leading domain-expert founders building software to transform the the economy, vertical by vertical.
Keep an eye out for our Part II on Vertical AI soon! Thanks for sticking with us for this lengthier essay and we look forward to your thoughts in the comments.
Pierce (2024). From Eliza to ChatGPT. The Verge.
Kosar (2023). Symbolic vs Connectionist Machine Learning. Valclav Kosar Blog.
Vaswani, Shzeer, Parmer, Uzkoreit, Gomez, Kaizer, Polosukhin (2017). Attention is All You Need. Google Brain.
Lubbad (2023). The Ultimate Guide to GPT-4 Parameters. Mohammed Lubbad Blog.
Cheng (2020). GPT-3: The Dream Machine in the Real World. Towards Data Science by Cheng He.
OpenAI (2005). Language Models are Few-Shot Learners. Arvix.org.
Schaeffer, Miranda, Koyejo (2023). Are Emergent Abilities of Large Language Models a Mirage? ArXiv.
UC Berkeley, UCSD, CMU, MBZUAI (2024). Chatbot Leaderboard. LMSYS.
Google (2023). We Have No Moat, And Neither Does OpenAI. Internal Memo.
Artificial Analysis (2024). Independent analysis of AI language models and API providers.
Accenture (2022). Unleashing the Full Potential of AI.
Villalobos, Ho, Sevilla, Besiroglu, Heim, Hobbhahn (2024). Will we run out of data? Limits of LLM scaling based on human-generated data. ArXiv.
Wolfram (2023). What Is ChatGPT Doing … and Why Does It Work? Stephen Wolfram Writings.
Columbus (2019). How Machine Learning Improves Manufacturing Inspections, Product Quality & Supply Chain Visibility. Forbes.
I couldn't agree more. Through the gen AI customers solutions we built during the last years in various industry verticals, we reached the same conclusion and we are building a vertical AI platform. Let's talk!