

Beauty and the VC
Consensus capital rewards familiar templates. Vertical AI winners must build their own
There was a popular newspaper game in the first half of the 20th century that asked people to guess which faces were the most “beautiful” from a set of 100 photos. Readers selected six faces, and their choices were then compared with those of all other players. If a player’s picks included the most popular face, they would win a prize.
Intrigued by the game as a possible model to explain price fluctuations in equity markets, British economist John Maynard Keynes discussed the optimal strategy in his 1936 book, The General Theory of Employment, Interest and Money. Keynes observed that the winning strategy was not to choose the face you found most attractive, but the face you believed everyone else would choose. And because everyone else could deploy the same strategy, to stay ahead, a person must think one step beyond everyone else—guessing others’ preferences, their guesses, what others think of those guesses, and so on. With each layer of analysis, the consideration drifts further from the original question: who is the most beautiful?
That recursion is now known as the Keynesian beauty contest. Keynes saw the same loop in markets: success in speculation comes less from picking the soundest asset than from guessing which one the crowd will bid up next, and when.
Venture capital now runs on the same logic, and the hyper-concentration of capital means ‘beauty’ is defined by an increasingly small number of players. This is the most concentrated venture capital market in history: roughly 75% of all venture dollars were raised by five firms in the first quarter of this year. In 2025, nearly 50% of VC dollars went into rounds greater than $500M — up from roughly 10% a decade ago.1
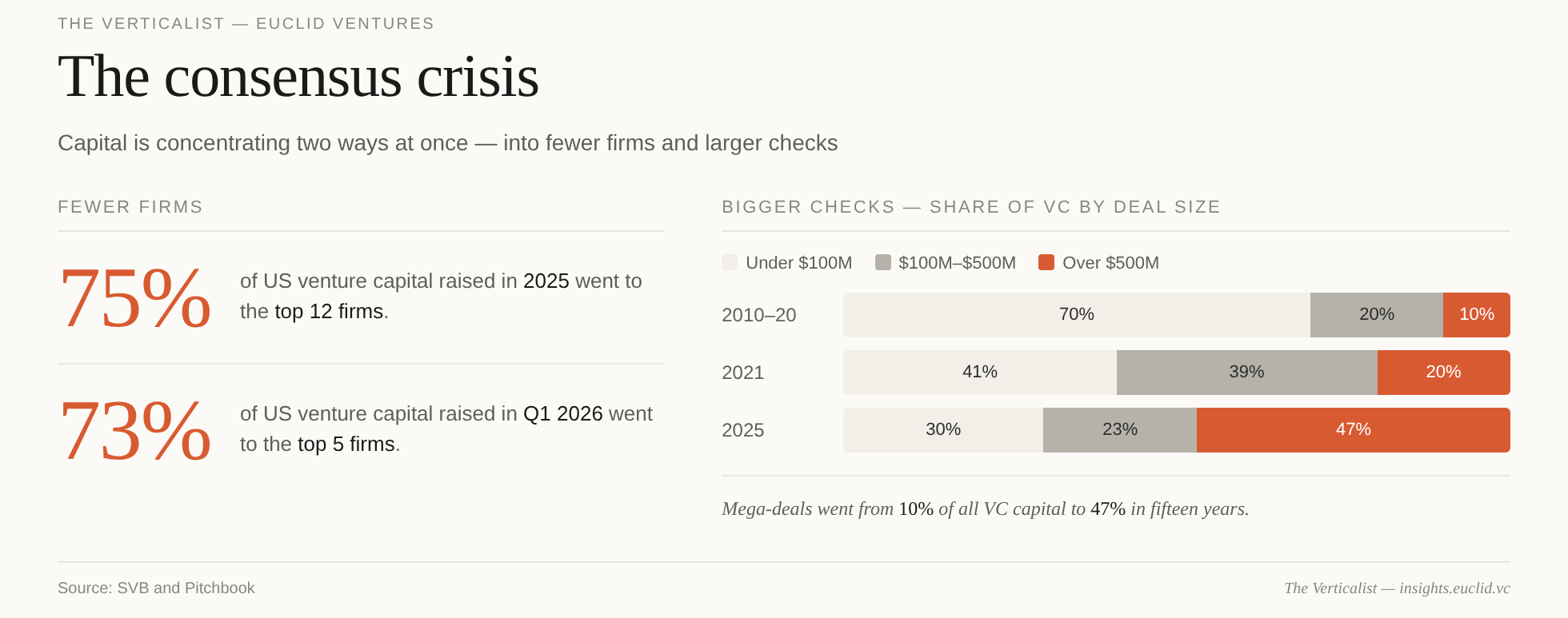
We’ve written about the structural side of this story before: the asset management theory of venture, the planned-economy dynamics, and the slow conversion of early-stage VC into an assembly-line market that prioritizes fundability over investability. What we wanted to expand on is the cognitive consequence — what consensus capital does to how investors think. In Vertical AI, that shift is especially dangerous because the thing being copied is not an idea, but a mistaken abstraction of a successful archetype.
When billions of dollars need to be deployed by a handful of decision-makers across a few hundred decisions a year, the firm's operating system has to rely on transferable templates. You cannot underwrite every company from first principles at that volume. So the operating system changes. You only invest in a narrow style of companies. You pattern-match on what worked before, outsource conviction to whoever bid before or after you, and compress every new opportunity into the shape of an old one. Pattern-matching isn’t a personality flaw of lazy investors. It’s the inevitable mechanism of scaled capital.
Pattern Matching, Predictably
Inevitable, however, isn’t the same as logically justified. Consensus capital didn’t invent pattern-matching — investors have always relied on it in some shape or form. What’s new is how narrow the band of acceptable patterns has become, and how punishing today’s venture market can be for those who diverge.
In a 2022 study of more than 16,000 startups and $9B of committed capital, Chicago Booth’s Diag Davenport found that roughly half of bad venture outcomes were predictable using only information available at the time of investment. The good-outcome model leaned on product characteristics. The bad-outcome model leaned heavily on the founder’s background. In a surprising twist, a model built solely on founder education data proved to be the single strongest predictor of which investments would underperform.
What’s striking is that this study isn’t telling venture anything it didn’t already know. It’s confirming one of its oldest adages, as Andy Rachleff described plainly: “When a great team meets a lousy market, the market wins. When a lousy team meets a great market, the market wins. When a great team meets a great market, something special happens.” In a recent essay, Dan Gray from Odin succinctly summarizes why this pattern occurs:
Somewhere along the way the industry convinced itself that the ability to raise capital was itself a desirable founder trait and this logic became recursive. Investors began pattern-matching on the founder archetype most likely to raise the next round, making that archetype easier to fund, reinforcing the pattern. —Dan Gray, Odin
That is the Keynesian’ beauty contest applied to hundreds of billions of dollars of venture capital. Ben Graham famously described the market as “a voting machine in the short run, a weighing machine in the long run.” Venture has gotten very good at voting. It has gotten worse at weighing.
Vertical AI Mad Libs
Walk into almost any demo day over the past year, and you’ll hear it:
“We’re [voice / agentic / services] AI for [vertical].”
This is not an indictment of founders but of the funding ecosystem. Founders use these formulations because incubators, accelerators, and investors want legible startups. And pattern matching by analogy is the easiest way to get there. But this is pattern matching at the worst possible level of abstraction. It’s not even pattern matching on markets or products. It’s pattern matching on the application of a model capability across markets, treating verticals as interchangeable substrates that a known template can be poured into.
The error compounds as the templates compound. Pattern matching on the technology template ("voice AI works”), the founder template ("ex-Stripe, technical, YC, young”), and the category template ("this worked in legal, so it will in another vertical”). This looks, from the outside, like a lot of analysis. It is not. None of those templates contains any actual constructive work on the market or the problem. The founding team’s insight into the market's shape and unique characteristics is the variable that determines whether the technology can achieve product-market fit.
Vertical markets are not fungible startup substrates. Legal looks nothing like supply chain, which looks nothing like construction. In fact, even most construction tech does not look like other construction tech. Construction is not one market, but the amalgamation of hundreds of markets. The technology may travel; the market dynamics never do. Document review and generation may be a multi-billion dollar problem in legal, but structurally irrelevant in construction. Pattern matching across verticals, or even sub-verticals, is a category error, treating the variable that matters most as if it were a constant.
In our essay on Vertical AI diffusion, we discussed how early Vertical AI breakouts are largely workflow enhancements: taking an existing task and using an LLM to make it cheaper or faster. Superficially, this is what templates copy when they replicate documentation tools like Harvey, Abridge, and EvenUp, or voice agents like Assort and Avoca.
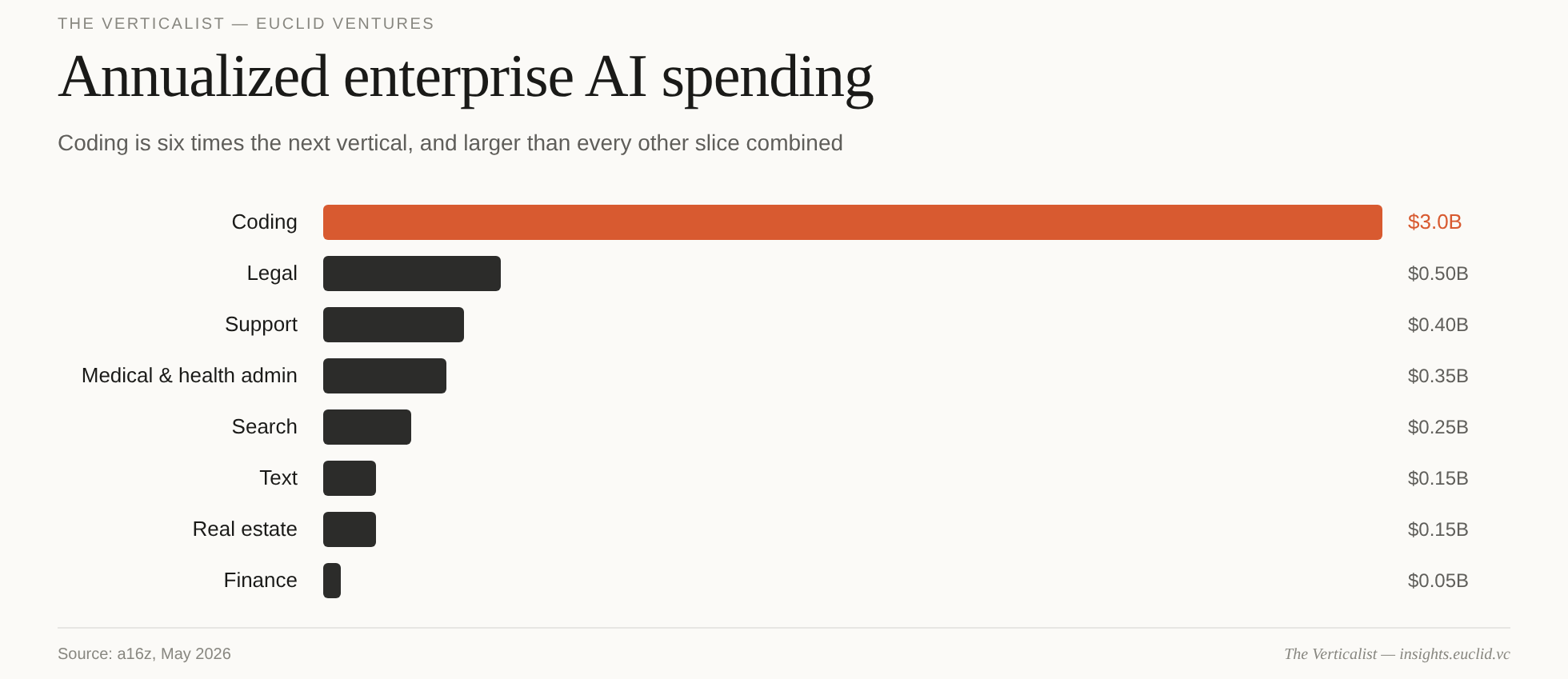
Even in the largest Vertical AI categories like legal, medical, and real estate, combined spending is only in the hundreds of millions. Coding (and to a lesser extent, legal) broke out because their market structures made AI adoption unusually favorable. Part of that is capability — LLMs are strong coding agents. But part of it is function. Software development is a rare category where the buyer is often the user, the output is digital, and the result is at least hypothetically measurable. Switching costs are also unusually low: developers can adopt and abandon coding agents much faster than most vertical workers can replace core workflow systems. Legal looks similar on the surface, but for different reasons: the corpus is large, the output is reviewable, and human judgment remains in the loop.
Anthropic’s own analysis speaks to this vertical heterogeneity. Its observed-exposure measure — which combines theoretical LLM capability with actual Claude usage in work settings — finds that LLMs could theoretically handle 88% of legal tasks versus observed exposure of 15%. That is the largest gap of any vertical on the chart. The model is not the main bottleneck. The diffusion of AI across idiosyncratic workflows across vertical markets is the constraint, and everything between theoretical capability (which will continue to increase as technology matures) and observed usage is where future Vertical AI applications will thrive.
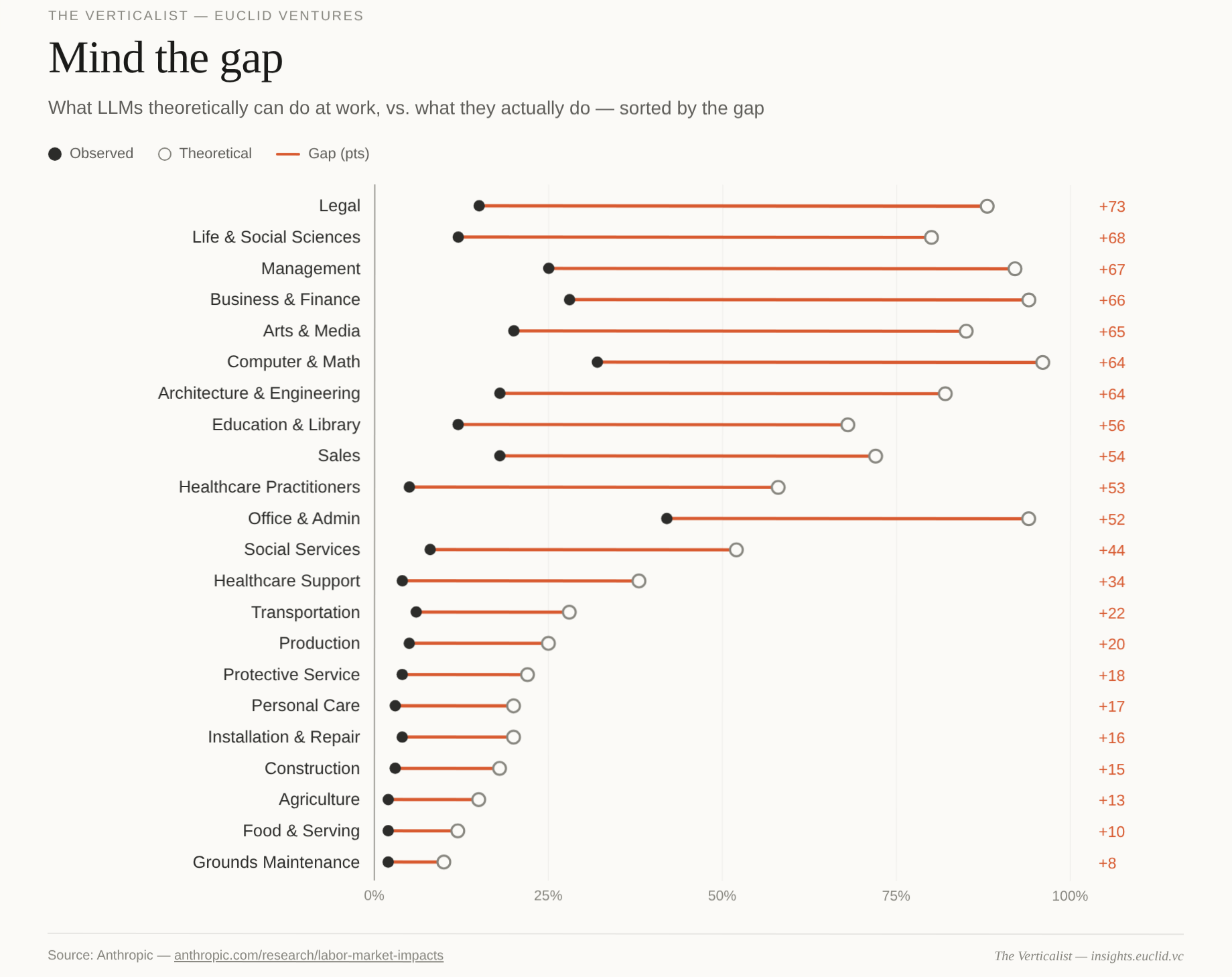
The frictions that define most real vertical workflows differ across markets. The pattern matchers look at existing vertical winners and try to template that deployment model across new sectors. But the real opportunity in vertical markets is not to copy what worked in one vertical into another in the hope of striking gold. It is to build new, vertical-specific Systems of Intelligences that can shrink the usage gap and create new categories. While the pattern matchers race to apply yesterday’s templates to new markets, the problem finders will reshape those markets with earned insights.
Problem Finding is the Job
A strong framing of what we call a vertical founder’s “earned insight” comes from a 2022 paper by Mattia Bianchi and Roberto Verganti. They argue that entrepreneurship has been systematically misunderstood as an exercise in problem-solving, when in fact it is primarily a problem-finding endeavor. The founder’s most important act, in their analysis, is identifying a problem worth solving. Everything else — the product, the go-to-market, the wedge — follows from the quality of that framing.
Dan Gray’s “centaur” concept gets at the same point: “rather than the tired question of jockey or horse, the investor’s job is to recognize the centaur.” The founder and the idea cannot be evaluated separately, because the idea is the material expression of how the founder believes the future of a market can be shaped with technology. Templated pattern matching starts with a known solution and searches for new markets to apply it. Problem finders work in the opposite direction: they start with the market, identify the problem others have missed, and only then decide where technology can attack it.
Our analysis of Vertical AI founders attempted to quantify the backgrounds of successful founders in the AI era. Seventy-one percent of $15M+ Vertical AI rounds in 2025 went to teams with prior domain experience. In other words, earned insight (i.e., successful problem-finding) into a vertical market was the strongest indicator of success.
Per the anti-expert argument, if AI truly democratizes domain knowledge — enabling technical founders to iterate and learn industries in weeks rather than years — then the vertical-founder advantage should shrink in vertical AI relative to vertical SaaS. AI-native, low-experience founders should be pulling ahead on attracting dollars and VCs, as the outsider disadvantage compresses.
Our analysis, however, shows the opposite. In Vertical AI, >70% of leading 2025-funded startups have founders with prior experience in or around their industry — and those founders raised deals 2.25x larger, with greater overall capital velocities, and higher VC scores. Every metric points in the same direction: the more AI-native the company, the more domain expertise matters, not less. — The Verticalist
Let us pre-empt the obvious objection: aren’t we now claiming that founder background is a strong predictor of success? Isn’t that just pattern matching?
No. The distinction is between pedigree and proximity. Pattern matching evaluates the founder against a narrow set of archetypes: school, prior startups, prior funding, network, and fundability. Problem finding evaluates the founder’s relationship to a specific market problem: what they know, what they have seen, and what they understand that outsiders miss.
Founder + Problem + Market
Underwriting early-stage Vertical AI should not be defined by the founder, the idea, or the market in isolation. It should be founder-plus-problem-plus-market, evaluated as a combined entity. Finding the problem within a market is closely intertwined with the structural shape of the opportunity and the founder’s frame for it. At Euclid, this allows us to evaluate opportunities from as early as inception-stage as founder+market+problem. As we discussed in our essay on PMF, we don’t mind investing pre-product and pre-revenue, but we do care about underwriting “identified market demand.”
There’s a through-line here to a piece we wrote early last year on market sizing in vertical markets, where we argued that the standard VC approach to TAM is backward-looking: it determines which categories are venture-scale based on past outcome sizes. We think early-stage vertical investors must train themselves to do the opposite: a forward-looking analysis that asks what a vertical will look like after AI reshapes it.
There’s the infamous example that many VC firms initially passed on Shopify because they perceived the market as too small. At the time, there were roughly 50K online stores, and most concluded that the market was too small for venture-scale returns. Of course, the missing critical insight was that by lowering the friction of launching an online store, Shopify created a much larger category in the process. Backward-looking TAM is another lazy pattern-matching exercise. Great teams with earned insights can create large, new categories. As we highlighted in our original market sizing essay, it’s not the market size at entry that matters; it’s the market at exit.
Evaluating the problem and market requires answers no template can provide. What is the urgency of this problem for buyers, and what gets unlocked when AI can be applied? Is the shape and scale of the problem widely found within the segment? Who are the natural buyers, and what do they already spend on the outcome the product produces, not the current tech spend? What’s the path from wedge to multi-product TAM expansion— which adjacent workflows are reachable, and where are the data & workflow loops that strengthen defensibility?
None of those questions can be answered solely by analogy to another vertical. There might be similarities, for certain, but templated analysis is doomed to fail, especially in new and rapidly expanding markets across Vertical AI. They require sitting with the market AND the problem alongside operators who will shape it. Nabeel Hyatt at Spark describes how he evaluates founders and distinguishes real executors from polished pitchers by examining what comes out of their hands: the product itself and the human behind it.
At our stage, the combination of market and problem largely stands in for product, but the premise still holds. We look for people who understand the day-to-day constraints of a vertical so deeply they can take the work apart — and who have enough technical instinct to rebuild it with AI. No matter the pace of LLM capabilities, we continue to believe problem-finding founders will remain the rate-limiting factor in industry transformation.
First Principles & Vertical Investing
From inside a large fund with a partnership that needs to see legible decisions, narrow pattern-matching is an inevitable outcome. The incentives are different but equally alluring downstream, as Rob Go from NextView illustrates:
As capital is concentrating, it's moving into a very narrow set of styles of company, and the companies that work within this narrow band raise more and more and more capital at higher and higher prices. And so, if you're a seed fund and your goal, you know, is to sustain yourself, not necessarily to like generate a great return like from an ultimate exit, but it's like, "Let me get a markup really fast and maybe multiple markups." It behooves you to then play that game. — Rob Go, NextView Ventures
There’s no denying the dopamine hit of quick markups. Combined with the desire to show strong performance metrics to a fund’s own investors, it’s an exceptionally strong incentive. As Howard Marks famously said, “you can’t eat IRR” — but you can raise your next fund (or accelerate your career) if you’re seen to be backing the consensus names.
Except the premise underneath that game is shakier than it looks. For all the talk of a closed circle of elite funds, the field of firms backing venture’s largest winners has widened substantially. In the 1990s, just 25 firms had at least one of the top ten deals in a given year, and five of them each captured more than 8% of all top deals over the decade. From 2005 to 2015, during a boom decade for new firm launches, 70 firms landed top-ten deals, and no single firm captured more than 8%. If you expect this dispersion to accelerate, as we do, then the era of consensus capital — where a handful of funds compress the industry into a single style of investing — is an inefficient planned economy. And planned economies misallocate capital by design.
The Imitation Game Will Have Few Winners
Set aside whether consensus even contains the winners, the game doesn’t pay even when it works.2 This is the Keynes beauty contest as played by today’s VC: the bet you’re really making is on the bidders, not the businesses — and the analysis drifts further and further from the original question: is this a good investment? And unlike a stock you can dump when sentiment turns, there’s no off-ramp when the music stops. There’s no crying in the casino. (Unless you convinced everyone your bespoke crypto thesis was actually about AI all along — in which case, congratulations.)
There’s a name for the posture this rewards. A few years ago, Glowforge’s Michael Natkin called out one of the tech industry’s favorite mantras — “strong opinions, loosely held” — as a glorification of toxic overconfidence. The original idea was sound: state your case hard, then update the instant the data turns. But the loosely held half rarely survives contact with practice, least of all in venture, where the feedback cycle runs long enough to bury the evidence. Deals get marked up, new funds get raised, and the conviction hardens.
We want to be clear about what we’re not saying. We’re not claiming that optimizing for problem finding and holistically evaluating team/problem/market will make you universally right. It doesn’t. We’re wrong more than we’re right. That’s the nature of the job: the base rate of being wrong at first check is undeniably high, and no framework fixes that.
But the humbling nature of the venture is no excuse to offload conviction or set aside rigor. Perhaps more importantly, seeking out problem finders doesn’t raise your hit rate so much as change what you’re holding when you do hit. Pattern matching crowds you into the same shrinking set of bets as everyone else, where being right pays little because conviction is borrowed, markets are crowded, and the price reflects the scale of consensus. Problem finding puts you in markets nobody else has underwritten, where being right — on the rare occasion you are — actually pays for all the times you weren’t. Meanwhile, shallow pattern matching is the operating system of consensus, the shortcut that lets concentrated capital deploy at scale without doing the market work underneath.
There is, of course, a certain irony here. The same instincts that once made a VC’s name — non-consensus, first-principles investing — now risk being recast as vectors of adverse selection. But the ones who hold their conviction — founders and investors alike — may be the ones who eventually look prescient. It makes the problem-finder’s patience cheap to acquire and expensive to hold, but in the long run, the market always wins.
In VC, playing the imitation game — backing startups predicated on the opinions of investors, allocators, or the market generally — is a tempting but fundamentally flawed strategy. What sets the greatest apart is their ability to find and commit to problems worth solving, regardless of what others may think.
Thanks for reading The Verticalist!
Euclid is an inception-stage VC built for Vertical AI founders. If anyone in your network is considering building in Vertical AI, we’d love to help. Just drop us a line via the comments below or on LinkedIn.
Data shows there’s very little evidence that king-making is a real phenomenon or a viable strategy for long-term startup success.

Great post. But arent you ascribing success to dollars raised here (which you critique yourself earlier in the post); Let us pre-empt the obvious objection: aren’t we now claiming that founder background is a strong predictor of success? Isn’t that just pattern matching?